
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 사랑
- Hvass-Lab
- Reinforcement Learning
- 머신러닝
- 강화학습
- neural networks
- 행복
- DeepLearning
- tensorflow
- 꿈
- machine learning
- Artificil Intelligence
- SQL
- 신경망
- deep learning
- 매크로
- 딥러닝
- 답변
- Andrej Karpathy
- 질문
- cs231n
- 인공지능
- SAS
- 세상
- Tutorial
- 번역
- TensorFlow Tutorials
- 한국어
- tutorials
- openai
- Today
- Total
목록SQL (11)
Economics & Deeplearning


 PROC SQL Tutorial 9 - outer join 3 : intersect
PROC SQL Tutorial 9 - outer join 3 : intersect
intersect 는 순서대로 intercept, intercept all, intercept corr, intercept all corr 임처음것은 공통된 것만, all은 중복허용, corr은 같이 있는 변수만, all corr은 중복되고 같이 있는 변수인데, 이 예제에서는 두 테이블에 공통된 값들만이 같이 있기 때문에 corr만 썼을 때와 같은 결과가 나타남
 PROC SQL Tutorial 8 - outer join 2
PROC SQL Tutorial 8 - outer join 2
수평적 결합이 inner left right full join 이었다면, 수직적 결합은 except intersect union outer union 임 all과 corr 명령어를 같이 쓸 수도 있음 proc sql;select *from one exceptselect *from two; 유니크한 애들만 남긴다. one 데이터셋에서 중복 관찰치를 지우고, one 과 two 가 만나는 부분도 제외함 proc sql; select * from one except all select * from two; one 에 있는 모든 관찰치는 다 쓰지만 two에 같이 있는 관찰치는 제외함 proc sql; select * from one except corr select * from two; 공통으로 있는 변수만을 남..
 PROC SQL Tutorial 7 - outer join 1
PROC SQL Tutorial 7 - outer join 1
outer join 에는 세가지가 있음 left, right, full 문법은 select ~ from ~ left join|right join|full join ~ on 으로 해결함 left outer join proc sql;select *from oneleft jointwoon one.x = two.x; right outer join proc sql;select *from oneright jointwoon one.x=two.x; full outer join proc sql;select *from onefull jointwoon one.x=two.x; data merged;merge three four;by x;run; proc sql;select three.x, a, bfrom threefull j..
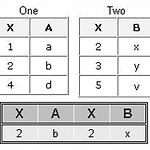 PROC SQL Tutorial 6 - inner join
PROC SQL Tutorial 6 - inner join
inner join 두 테이블에서 같은 값을 가지는 변수만을 남김 변수명은 달라도 상관없음 proc sql;select *from one, twowhere one.x = two.x; data step으로 하는 법 data merged;merge one two;by x; run; proc sql;select one.x, a, bfrom one, twowhere one.x = two.xorder by x; table alias를 이용할 수도 있음 proc sql;select staffmaster.empid, lastname, firstname, jobcode from sasuser.staffmaster, sasuser.payrollmaster where staffmaster.empid=payrollmaste..
 PROC SQL Tutorial 5 - join(cartesian product)
PROC SQL Tutorial 5 - join(cartesian product)
join 은 data step에서 merge나 set과 비슷함 join 은 항상 cartesian product로 시작함 proc sql; select * from one, two; 이와 같은 그림이 카르테시안 프로덕트임덧씌워지지 않고 모든 값들의 곱을 나타내줌각 데이터셋이 1000개의 관찰치를 가지고 있다면, 1,000 * 1,000 = 1,000,000개의 관찰치가 생김
subqueries란 쿼리 안에 다시 쿼리가 있어서 그 결과를 having 절이나 where 절에 이용하는 것임 예를 들어,proc sql; select jobcode, avg(salary) as avgsalary from sasuser.payrollmaster group by jobcode having avg(salary) > (select avg(salary) from sasuser.payrollmaster); 위의 코드는 전체 평균보다 큰 jobcode 코드만 찾아내는 코드임 subquery 에는 특정 연산자를 이용할 수 있음, all, any, exists 임 >any가장 작은 값보다 큰 것들all가장 큰 값보다 큰 것들 exists서브쿼리에 있는 값 중 하나라도 필요할 경우not exists서브..
proc sql; create table work.miles as select salcomps.empid, lastname, newsals.salary, newsalary from sasuser.salcomps, sasuser.newsals where salcomps.empid=newsals.empid order by 2;quit; 위의 예제를 해석하면 다음과 같음sasuser.salcomps와 sasuser.newsals 두 개의 데이터셋에서 데이터를 불러와 카르테시안 곱의 데이터셋을 만들고, 그중 salcomps데이터셋에 empid 변수와 newsals 데이터셋에 empid 변수가 같은 것만을 남긴다. 그 이후에 empid는 salcomps 데이터셋에서 불러오고, lastname은 하나의 변수에만 있..
proc sql; select membertype, sum(milestraveled) as totalmiles from sasuser.frequentflyers group by membertype;quit; 위의 예제를 해석하면 다음과 같음sasuser.frequentflyers 데이터셋에서 불러와서 membertype과 totalmiles를 만드는데, totalmiles는 milestraveled 변수에다가 sum 함수를 적용시킨 값임 (sum 뿐만 아니라, mean이나 count, cv, max, min 등도 적용할 수 있음) 마지막으로 membertype에 따라 그룹지어서, 결과값을 나타내줌